In this blog we’re going to step a bit away from Amazon Connect and focus on building a conversational interface using Amazon Lex. As you can probably guess down the line, this interface/bot is going to be connected to Amazon Connect for even more contact center goodness. Here we’re going to focus on creating a Lambda function strictly for validation, not for fulfillment.
First, let’s talk about what I’m building. I’m building a bot which can schedule a time to have a call with me. You tell your intention to the bot “schedule a meeting/call” and the bot will then ask you a few questions using directed language to figure out when you want to meet. Once Lex has all the information it needs it goes out to my calendar to figure out if I’m free or busy. Second, the validation code I have is mainly based on one of Amazon’s great blueprint for ordering flowers. I recommend you start with that before trying to write your own from scratch. Finally, read through the code and pay close attention to the comments marked in bold as these were the biggest gotchas as I went through.
A couple of things to keep in mind when building a conversation interface with Amazon Lex and you’re using validation.
– Have a clear scope of the conversation. I’m not a VUI designer by any means, but if you’re planning on going with an open-ended prompt “How may I help you?” you will be working on this for a long time. Instead try to focus on the smallest possible outcome. Ultimately, it is my opinion that no IVR is really NLU and they are all just directed speech apps with a lot more money sunk into them so they can be called NLU IVRs.
– If you’re going to use input validation, every user input will be ran through Lambda. This means that you must account for people saying random things which aren’t related to what your bot does and these random things will be processed through the validation function and might generate errors. Thus, you need to ignore this input and direct the customer to answer your question, so you can move on.
– Separating validation from fulfillment makes the most sense. Other than making your code easier to read and manage, you’re also able to separate responsibilities and permissions between your two Lambda functions.
– Play around with the examples Amazon provides. They are a great tool to get started and give you a ton of building blocks you can use in your own bot.
Here’s the validation code as well as some notes, hopefully this helps someone else along the way.
'use strict';
// --------------- Helpers to build responses which match the structure of the necessary dialog actions -----------------------
//elicitSlot is in charge of building the request back to Lex and tell Lex what slot needs to be re-filled.
function elicitSlot(sessionAttributes, intentName, slots, slotToElicit, message) {
return {
sessionAttributes,
dialogAction: {
type: 'ElicitSlot',
intentName,
slots,
slotToElicit,
message,
},
};
}
function close(sessionAttributes, fulfillmentState, message) {
return {
sessionAttributes,
dialogAction: {
type: 'Close',
fulfillmentState,
message,
},
};
}
function delegate(sessionAttributes, slots) {
return {
sessionAttributes,
dialogAction: {
type: 'Delegate',
slots,
},
};
}
function confirm(sessionAttributes, intentName, slots){
return{
sessionAttributes,
dialogAction:{
type: 'ConfirmIntent',
intentName,
slots,
message: {
contentType: 'PlainText',
content: 'We are set, do you want to schedule this meeting?'
}
},
};
}
// ---------------- Helper Functions --------------------------------------------------
function isDateWeekday(date) {
const myDate = parseLocalDate(date);
if (myDate.getDay() == 0 || myDate.getDay() == 6) {
console.log("Date is a weekend.");
return false;
} else {
console.log("Date is a weekday.");
return true;
}
}
function parseLocalDate(date) {
/**
* Construct a date object in the local timezone by parsing the input date string, assuming a YYYY-MM-DD format.
* Note that the Date(dateString) constructor is explicitly avoided as it may implicitly assume a UTC timezone.
*/
const dateComponents = date.split(/\-/);
return new Date(dateComponents[0], dateComponents[1] - 1, dateComponents[2]);
}
function isValidDate(date) {
try {
return !(isNaN(parseLocalDate(date).getTime()));
} catch (err) {
return false;
}
}
function buildValidationResult(isValid, violatedSlot, messageContent) {
if (messageContent == null) {
return {
isValid,
violatedSlot,
};
}
return {
isValid,
violatedSlot,
message: { contentType: 'PlainText', content: messageContent },
};
}
function validateMeeting(meetingDate, meetingTime, meetingLength) {
if (meetingDate) {
if (!isValidDate(meetingDate)) {
return buildValidationResult(false, 'MeetingDate', 'That date did not make sense. What date would you like to meet?');
}
if (parseLocalDate(meetingDate) < new Date()) {
return buildValidationResult(false, 'MeetingDate', 'You can only schedule meetings starting the next business day. What day would you like to meet?');
}
if (!isDateWeekday(meetingDate)) {
return buildValidationResult(false, 'MeetingDate', 'You can only schedule meetings during the normal weekday. What day would you like to meet?');
}
if (meetingTime) {
if (meetingTime.length !== 5) {
// Not a valid time; use a prompt defined on the build-time model.
return buildValidationResult(false, 'MeetingTime', null);
}
const hour = parseInt(meetingTime.substring(0, 2), 10);
const minute = parseInt(meetingTime.substring(3), 10);
if (isNaN(hour) || isNaN(minute)) {
//Not a valid time; use a prompt defined on the build-time model.
return buildValidationResult(false, 'MeetingTime', null);
}
if (hour < 10 || hour > 16) {
//Outside of business hours
return buildValidationResult(false, 'MeetingTime', 'Meetings can only be scheduled between 10 AM and 4 PM. Can you specify a time during this range?');
}
}
if(!meetingLength){
return buildValidationResult(false, 'MeetingLength', 'Will this be a short or long meeting?');
}
}
return buildValidationResult(true, null, null);
}
//--------------- Functions that control the bot's behavior -----------------------
function orderFlowers(intentRequest, callback) {
const source = intentRequest.invocationSource;
//get appointment slots
const meetingDate = intentRequest.currentIntent.slots.MeetingDate;
const meetingTime = intentRequest.currentIntent.slots.MeetingTime;
const meetingLength = intentRequest.currentIntent.slots.MeetingLength;
//For fullfilment source will NOT be DialogCodeHook
if (source === 'DialogCodeHook') {
//Perform basic validation on the supplied input slots. Use the elicitSlot dialog action to re-prompt for the first violation detected.
const slots = intentRequest.currentIntent.slots;
const validationResult = validateMeeting(meetingDate, meetingTime, meetingLength);
if (!validationResult.isValid) {
slots[`${validationResult.violatedSlot}`] = null;
callback(elicitSlot(intentRequest.sessionAttributes, intentRequest.currentIntent.name, slots, validationResult.violatedSlot, validationResult.message));
return;
}
//Pass the price of the flowers back through session attributes to be used in various prompts defined on the bot model.
const outputSessionAttributes = intentRequest.sessionAttributes || {};
callback(delegate(outputSessionAttributes, intentRequest.currentIntent.slots));
return;
}
}
// --------------- Intents -----------------------
function dispatch(intentRequest, callback) {
const intentName = intentRequest.currentIntent.name;
//Dispatch to your skill's intent handlers
if (intentName === 'MakeAppointment') {
return orderFlowers(intentRequest, callback);
}
throw new Error(`Intent with name ${intentName} not supported`);
}
//--------------- Main handler -----------------------
//Route the incoming request based on intent.
//The JSON body of the request is provided in the event slot.
//Execution starts here and moves up based on function exports.handler => dispatch =>orderFlowers=>validateMeeting=>buildValidationResult is the most typical path a request will take.
exports.handler = (event, context, callback) => {
try {
dispatch(event, (response) => callback(null, response));
} catch (err) {
callback(err);
}
};


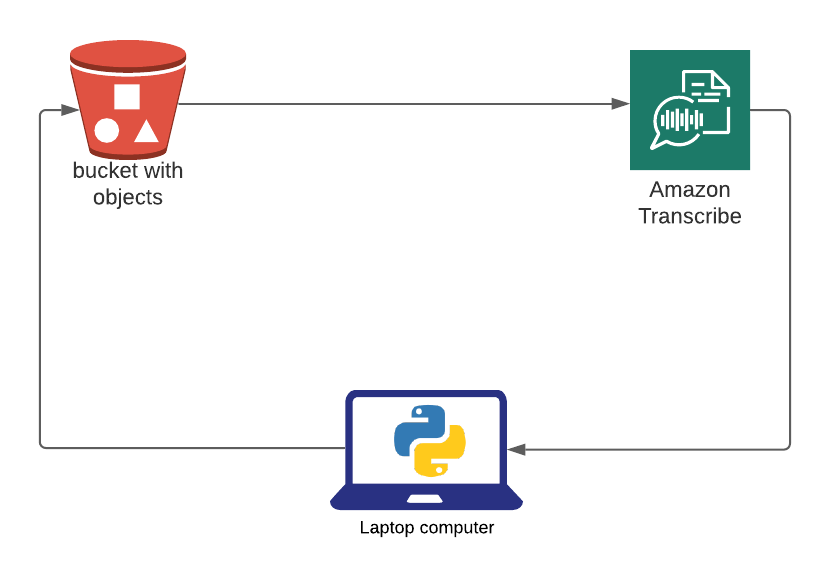 * I have many AWS profiles, which might not the be case for others. If you only have a single profile change this line session = boto3.session.Session(profile_name=’MyProfile’) to session = boto3.session.Session()
* I have many AWS profiles, which might not the be case for others. If you only have a single profile change this line session = boto3.session.Session(profile_name=’MyProfile’) to session = boto3.session.Session()



 The last 3 commits were successfully built (sent to Lambda). You can click on the commit and see detailed information on the results of every command in your yml file. You’re done, you’ve developed some code locally, committed to git, and pushed it to Lambda all with a few clicks.
The last 3 commits were successfully built (sent to Lambda). You can click on the commit and see detailed information on the results of every command in your yml file. You’re done, you’ve developed some code locally, committed to git, and pushed it to Lambda all with a few clicks.


You must be logged in to post a comment.