I’m a stickler for documentation and a bigger stickler for good documentation. Documentation allows the work you’ve produced to live on beyond you and help others get up to speed quickly. It feels that documentation is one of those things everyone says they do, but few really follow through. There’s nothing hard about it, but it’s something you need to work on as you’re going through your project. Do not leave documentation to the end, it will show. So DO IT!
I’ve recently started a new project to migrate an IVR over to CVP. To my pleasant surprise the customer had a call flow, prompts, a web service definition document, and test data. A dream come true! As I started the development I noticed that the verbiage in the prompts didn’t match the call flow and considering my “sticklerness” I wanted to update the call flow to ensure it matches 100% with the verbiage.
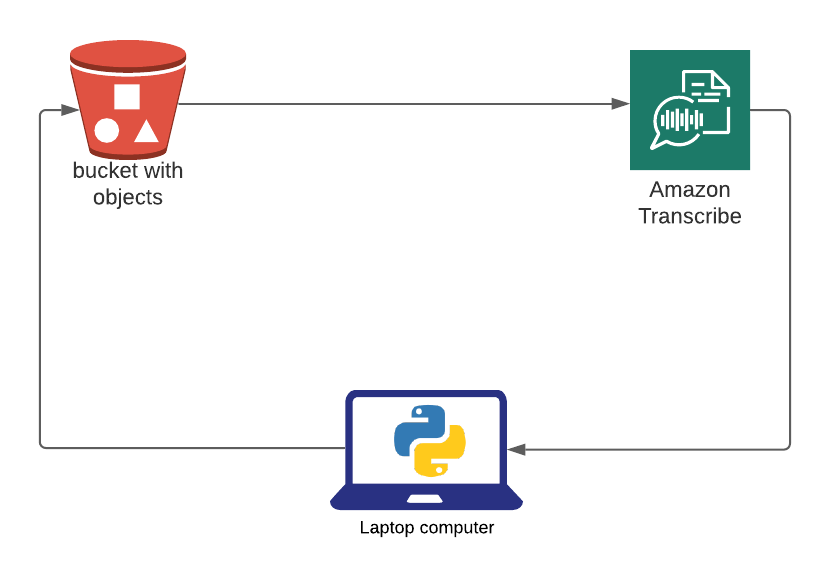
I’m always looking for excuses to play around with Python, so that’s what I used. I hacked together the script below which does the following:
- Creates an AWS S3 bucket.
- Uploads prompts from a specific directory to bucket.
- Creates a job in AWS Transcribe to transcribe the prompts.
- Waits for the job to be completed.
- Creates a CSV names prompts.csv
- Deletes transcriptions jobs
- Deletes bucket
The only things you will need to change to match what you’re doing is the following:
local_directory = 'Spanish/'
file_extension = '.wav'
media_format = 'wav'
language_code = 'es-US'
The complete code is found below, be careful with the formatting it might be best to use copy it from this snippet:
</pre>
<pre>from __future__ import print_function
from botocore.exceptions import ClientError
import boto3
import uuid
import logging
import sys
import os
import time
import json
import urllib.request
import pandas
local_directory = 'French/'
file_extension = '.wav'
media_format = 'wav'
language_code = 'fr-CA'
def create_unique_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_unique_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
)
# print(bucket_name, current_region)
return bucket_name, bucket_response
def delete_all_objects(bucket_name):
res = []
bucket = s3Resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
# print(res)
bucket.delete_objects(Delete={'Objects': res})
s3Client = boto3.client('s3')
s3Resource = boto3.resource('s3')
transcribe = boto3.client('transcribe')
data_frame = pandas.DataFrame()
# Create bucket
bucket_name, first_response = create_bucket(
bucket_prefix = 'transcription-',
s3_connection = s3Client)
print("Bucket created %s" % bucket_name)
print("Checking bucket.")
for bucket in s3Resource.buckets.all():
if bucket.name == bucket_name:
print("Bucket ready.")
good_to_go = True
if not good_to_go:
print("Error with bucket.")
quit()
# enumerate local files recursively
for root, dirs, files in os.walk(local_directory):
for filename in files:
if filename.endswith(file_extension):
# construct the full local path
local_path = os.path.join(root, filename)
print("Local path: %s" % local_path)
# construct the full Dropbox path
relative_path = os.path.relpath(local_path, local_directory)
print("File name: %s" % relative_path)
s3_path = local_path
print("Searching for %s in bucket %s" % (s3_path, bucket_name))
try:
s3Client.head_object(Bucket=bucket_name, Key=s3_path)
print("Path found on bucket. Skipping %s..." % s3_path)
except:
print("Uploading %s..." % s3_path)
s3Client.upload_file(local_path, bucket_name, s3_path)
job_name = relative_path
job_uri = "https://%s.s3.amazonaws.com/%s" % (
bucket_name, s3_path)
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat=media_format,
LanguageCode=language_code
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print('Transcription ' + status['TranscriptionJob']['TranscriptionJobStatus'])
time.sleep(25)
print('Transcription ' + status['TranscriptionJob']['TranscriptionJobStatus'])
response = urllib.request.urlopen(status['TranscriptionJob']['Transcript']['TranscriptFileUri'])
data = json.loads(response.read())
text = data['results']['transcripts'][0]['transcript']
print("%s, %s "%(job_name, text))
data_frame = data_frame.append({"Prompt Name":job_name, "Verbiage":text}, ignore_index=True)
print("Deleting transcription job.")
status = transcribe.delete_transcription_job(TranscriptionJobName=job_name)
#Create csv
print("Writing CSV")
data_frame.to_csv('prompts.csv', index=False)
# Empty bucket
print("Emptying bucket.")
delete_all_objects(bucket_name)
# Delete empty bucket
s3Resource.Bucket(bucket_name).delete()
print("Bucket deleted.")</pre>
<pre>
I hope this helps someone out there create better documentation.
~david
 * I have many AWS profiles, which might not the be case for others. If you only have a single profile change this line session = boto3.session.Session(profile_name=’MyProfile’) to session = boto3.session.Session()
* I have many AWS profiles, which might not the be case for others. If you only have a single profile change this line session = boto3.session.Session(profile_name=’MyProfile’) to session = boto3.session.Session()
You must be logged in to post a comment.