I’ve been on a text-to-speech and speech-to-text kick lately. My last post talked about using AWS S3 and Amazon Transcribe to convert your audio files to text and in previous articles I’ve covered how to create temporary prompts using Poly so you can build out your contact center call flows. Well, now we’re going to expand our use case to allow a traditional on premise call center to leverage the cloud and provide dynamic prompts. My use case is simple. I want my UCCX call center to dynamically play some string back to my caller without having to use a traditional TTS service.
First, this is not new in any way and other people have solved this in different ways. This Cisco DevNet Github repo provides a method to use voicerss.org to generate TTS for UCCX. However, this process requires loading a jar file in order to do Base64 decoding. Then there’s this Cisco Live presentation from 2019, by the awesome Paul Tindall, who used a Connector server to do something similar. To be fair the Connector server allowed for a ton more functionality than what I’m looking for.
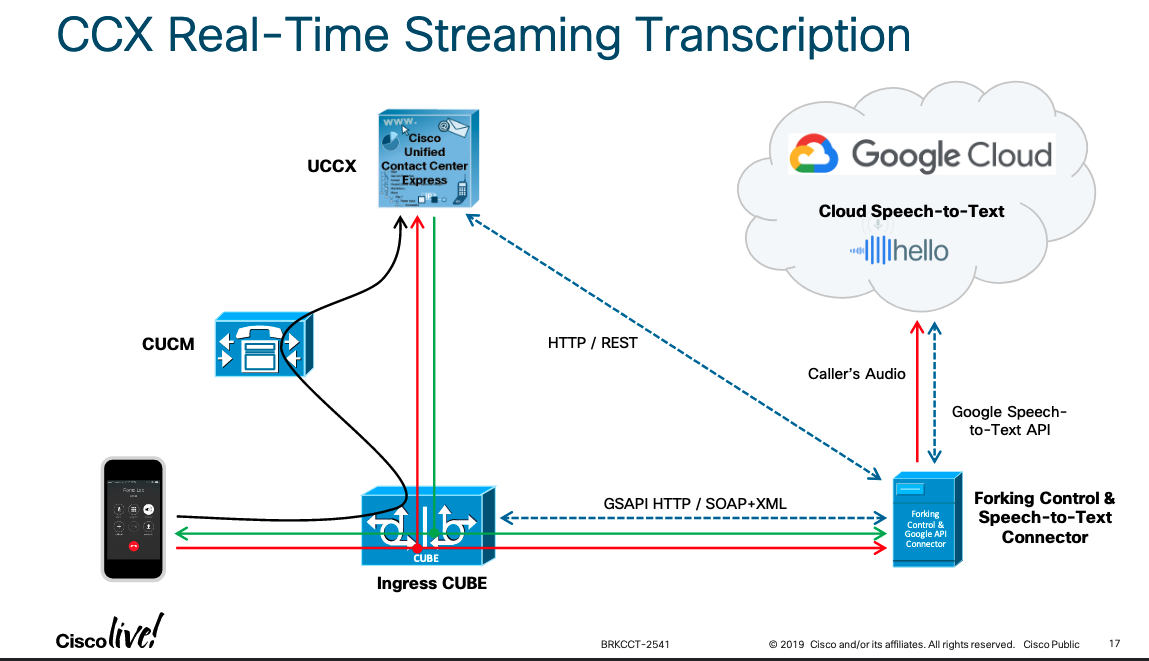
Cisco Live Presentation
Second, I wanted this functionality to be as easy to use as possible. While functionality keeps getting better for on premise call center software there are still limitations around knowledge to leverage new features and legacy version that can’t be upgraded that makes it harder to consume cloud based services. I wanted the solution to require the least amount of moving parts possible. That means no custom Java nor additional servers to stand up.
The solution I came up with leverages Google’s cloud (GCP) specifically Cloud Functions. However, the same functionality can be achieves used AWS Lambda or Azure’s equivalent. At a high level we have an HTTP end point where you pass your text string to and in return you will get a wav file in the right format which you can then play back.
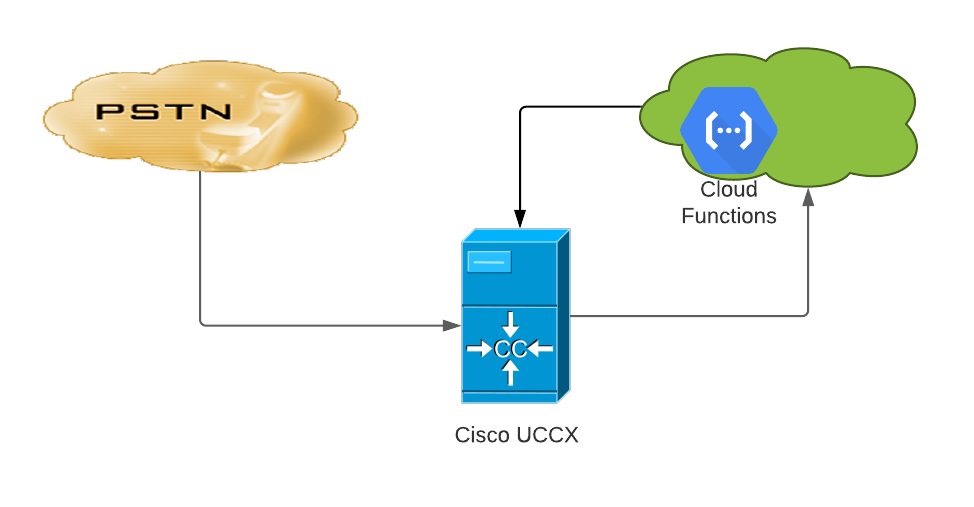
Flow Diagram
The URL would look something like this:
https://us-central1-myFunction.cloudfunctions.net/synthesize_text_to_wav?text=American%20cookies%20are%20too%20big
The Good Things About This
- Pay as you go pricing for TTS. Looking at the pricing calculator a few hours of TTS a month would run under $2.00/month.
- Infinitely scalable. If you’re handling 1 call or 100 calls your function will always return data.
- Easy to use.
The Bad Things About This
- There is a delay between making the request and getting the wav file. I’ve seen as long as 7 seconds at times. I would only use this in a very targeted manner and ensure it didn’t affect the caller experience too drastically.
- Requires your on premise IVR to have internet access. Often time this is a big no no for most businesses.
Some initial testing with UCCX is showing some positive results. I’m going to investigate if there’s a way to accelerate the processing in order to keep the request and response in under 3 seconds as well as adding the ability to set language, voice, and even SSML via arguments. If you want to build this yourself here’s the code for the function.
def synthesize_text_to_wav(request):
"""Synthesizes speech from the input string of text."""
text = request.args.get('text')
client = texttospeech.TextToSpeechClient()
input_text = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US",
name="en-US-Standard-C",
ssml_gender=texttospeech.SsmlVoiceGender.FEMALE,
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
response = client.synthesize_speech(
request={"input": input_text, "voice": voice, "audio_config": audio_config}
)
src_file_path = '/tmp/output.mp3'
dst_file_path = '/tmp/output.wav'
# make sure dir exist
os.makedirs(os.path.dirname(src_file_path), exist_ok=True)
# The response's audio_content is binary.
with open(src_file_path, "wb") as out:
out.write(response.audio_content)
print('Audio content written to file "output.mp3"')
AudioSegment.from_mp3(src_file_path).export(dst_file_path, format="wav", codec="pcm_mulaw", parameters=["-ar","8000"])
return send_file(dst_file_path
Be awesome!
~david
You must be logged in to post a comment.